
skipfishは、googleで開発されたWebアプリケーション診断ツールです。
これで自分のサイトを診断してみます。
最近立てたばかりのラズパイ4B上のサイトです。サイトの中身は何もありません。


自分の管理下以外のサーバーを検査するのは迷惑行為に当たるので止めましょう
起動
kali ー 01-Reconnaissance ー Web Vulnerability Scanning ー skipfishで起動
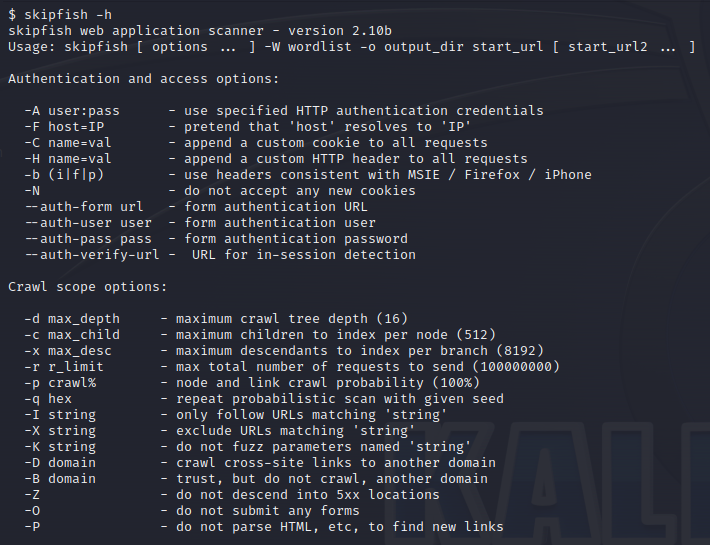
ターミナルが起動してヘルプ画面が立ち上がります。
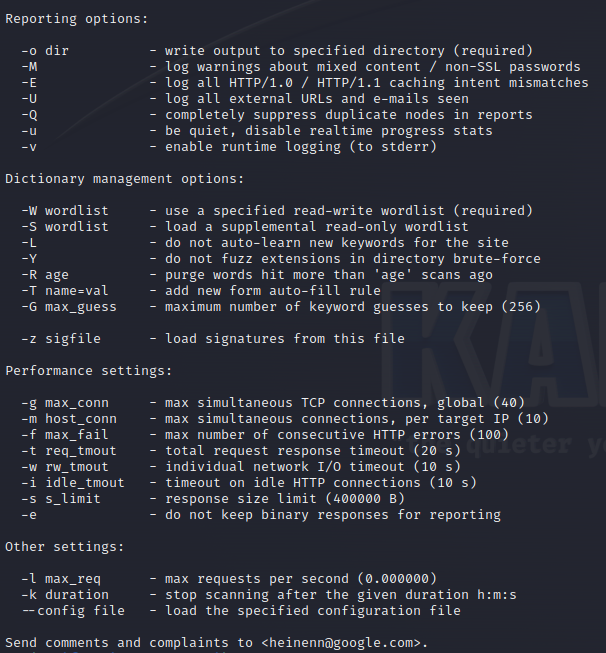
保存先フォルダの指定
最低限の必要なオプションは、調査結果を保存するフォルダの設定です。
ここでは ” reports ” というフォルダ(Linuxではディレクトリと呼びます)を作り、保存先に指定します。
フォルダは空のフォルダを用意します。
下記コマンドで、まずはフォルダ(ディレクトリ)を作成します。
mkdir reports
” reports ” フォルダが作成されました。

キーワードファイルの作成
サイトから集めてきたキーワードを書き込むファイルを作成します。
touch ファイル名
ここでは ” keywords ” というファイルを作成しました。

” keywords ” ファイルが作成されています。
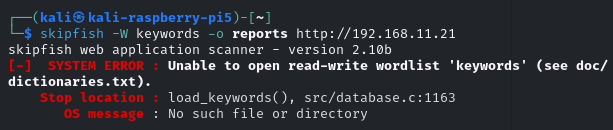
ちなみに、予めファイルを作らずに実行するとこのようなエラーが出て怒られます。
skipfishの実行
以下のコマンドで実行します。
skipfish -W キーワードファイル -o 保存先フォルダ 調査したいサイト
以下のコマンドで自分のラズパイ4Bサイトを調査しました。
skipfish -W keywords -o reports http://192.168.11.21

中身の無いサイトなので数秒で完了しました。
普通のサイトでは(規模にもよりますが)数分以上かかります。(中止は ” Ctrl + C ” )
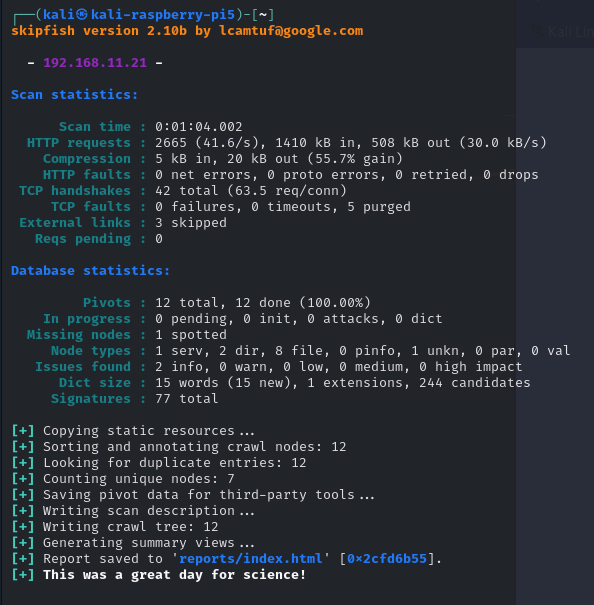
実行結果
ターミナル
ターミナルには概要が表示されます。
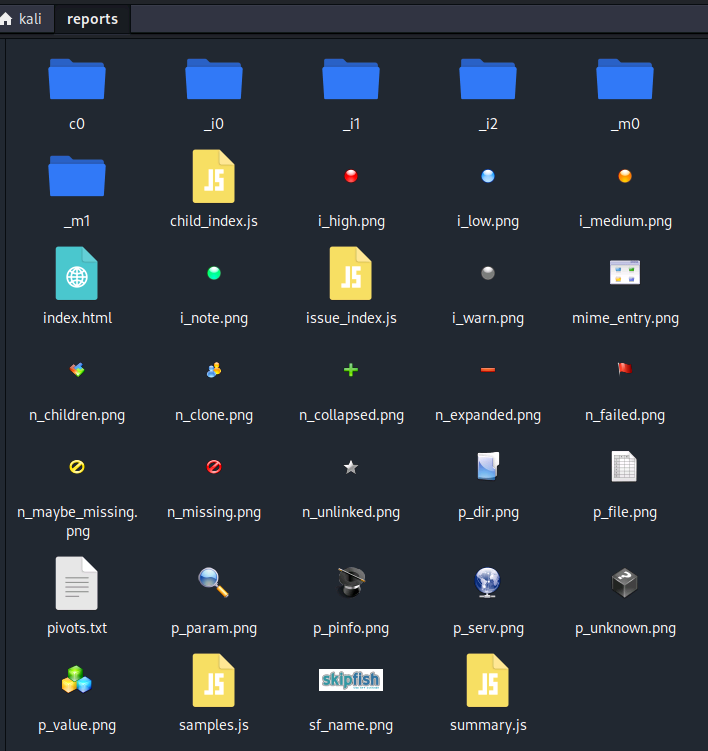
保存先フォルダ
保存先フォルダ(ディレクトリ)の中にはこのようなファイル群があります。
” index.html ” ファイルを、ブラウザで開きます。(右クリックでブラウザで開く)
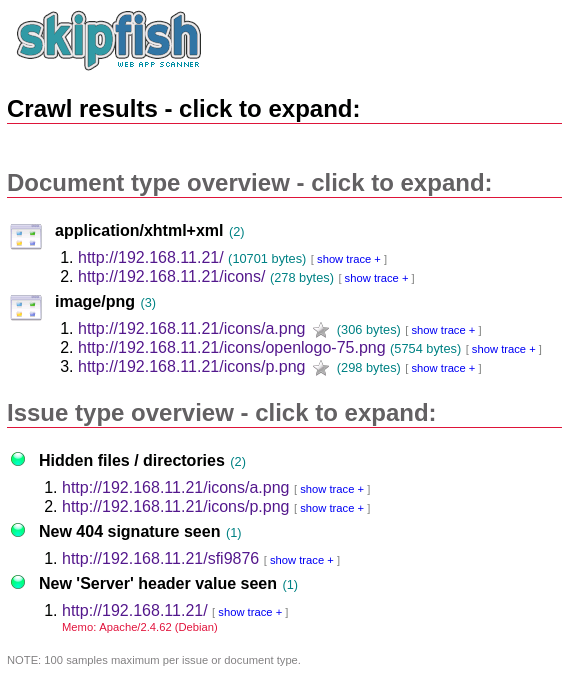
ブラウザで開いた結果。
何しろ中身の無いサイトなのであまり見るべき結果がありません。

それぞれをクリックすると詳細が表示されます
キーワードファイル
キーワードファイルは2つに増えています。
” keyword.old ” ファイルは旧ファイルのコピーであり、中身の無いファイル。
” keyword ” ファイルの中身は以下の通り、サイトから収集してきたキーワードが記録されています。
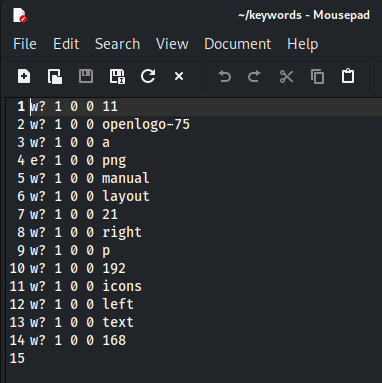
14語が記録されています。
まとめ
skipfishの使い方について概説しました。
今回は中身のないサイトの診断でしたが、実際には各種の脆弱性を診断してくれるようです。
本投稿の環境はRaspberryPi5のkali-Linuxで行っています。


コメント