
Linuxの cut コマンドは、テキストの行から特定の文字やフィールドを抽出するコマンドです。
ログファイルやCSVなどの整形済みデータを扱う際に役立ちます。
各行のフィールドの並び順が全て同じになっている表から、特定の縦の列だけを切り出す場合など。
コマンドの実行例
例えば下図のようなファイルがある場合、特定の列だけを取り出したい場合に使われます。
a1 , b1 , c1 , d1
a2 , b2 , c2 , d2
a3 , b3 , c3 , d3
a4 , b4 , c4 , d4
a5 , b5 , c5 , d5
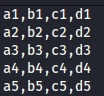
例としてファイル名は ” table01.txt ” とします。
使うオプションは ” -d ” と ” -f ” をペアで使います。
- ” -d ” は区切り文字を指定する(何も指定しなければTABが区切りとなる)
- ” -f ” は区切られたフィールドの何番目かを指定する
構文は以下の通り
cut -d’区切り記号’ -f列番号 対象FILE
具体例では
cut -d’,’ -f2 table01.txt
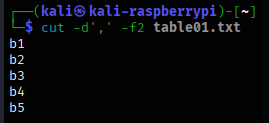
となります。
a1 , b1 , c1 , d1
a2 , b2 , c2 , d2
a3 , b3 , c3 , d3
a4 , b4 , c4 , d4
a5 , b5 , c5 , d5
元の表の2列目だけが抽出されています。
取り出したい列が複数ある場合は数字をコンマで区切ります。
2列目と3列目を切り出したい場合は、
cut -d’,’ -f2,3 table01.txt
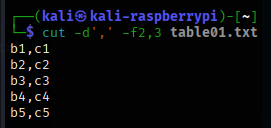
a1 , b1 , c1 , d1
a2 , b2 , c2 , d2
a3 , b3 , c3 , d3
a4 , b4 , c4 , d4
a5 , b5 , c5 , d5
実際の例
コンマで区切られ規則正しく並んだcsv形式の表から列を抜き出すことが主な使い方かと思います。
ここではログから特定の列の抽出に利用してみます。(行の抽出は ” grep ” が利用できます)
例えば下のログの2列目を抽出してみます。(ファイル名は ” /var/log/clamav/freshclam.log ” で、開くには ” sudo ” が必要です)
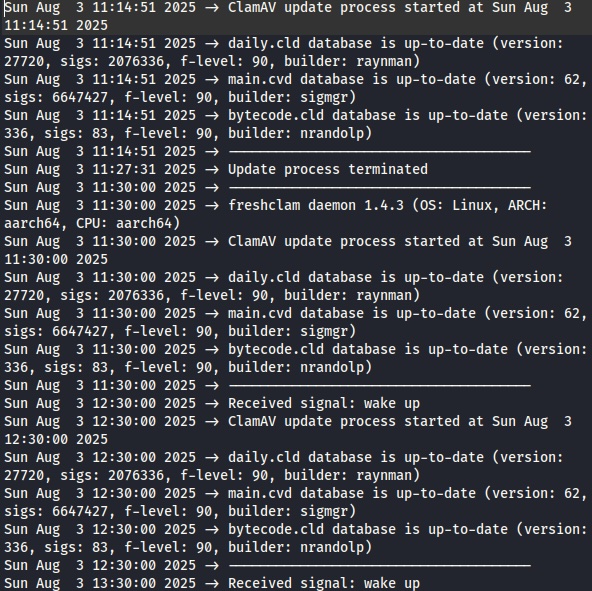
このログは ” ” (スペース)によって区切られていますので、区切り文字は ” ” を指定します。
sudo cut -d” ” -f2 /var/log/clamav/freshclam.log
2列目のみが抽出されています。
スペース区切りの場合、スペースの数が一定でない表では ” cut ” コマンドは不向きです。(柔軟な切り出しには ” awk ” などの別コマンドを使います)
その他の使い方
使う場面は限られると思いますが、特定の文字を抽出することができます。
echo “abcdef” | cut -b 2-4
“abcdef”の文字列のうち、2から4バイト目の文字を出力する例です。
結果は “bcd” となります。
echo “abcdef” | cut -c 2-4
“abcdef”の文字列のうち、2から4文字目の文字を出力する例です。
結果は “bcd” となります。
これらのオプションは日本語のような2バイト文字の処理には不向きです。
まとめ
演算を伴う高度な列抽出には、 ” awk ” コマンドなどを用います。
” awk ” 以外にも ” awk ” から派生した、 ” gawk ” , ” nawk ” , ” mawk ” コマンドがありますが、機会あれば取り上げます。


コメント